最近uu加速器可白嫖《守望先锋》,啥子1个月内,用uu加速累计24h就可以白嫖了,奈何太多白嫖怪,每日11:00放送资源时,服务器就爆炸了,好不容易进去后,又显示请你明天再来,…(⊙_⊙;)…这就很让人炸裂了….
起
最近uu加速器可白嫖《守望先锋》,啥子1个月内,用uu加速累计24h就可以白嫖了,奈何太多白嫖怪,每日11:00放送资源时,服务器就爆炸了,好不容易进去后,又显示请你明天再来,…(⊙_⊙;)…这就很让人炸裂了.
承
作为一个写程序的怎么能挤不赢别人?因为领取步骤会跳很多网页验证登录啥子的,能不能直接跳到最后一步领取呢?显而易见,抓包试试.
转
Fiddler的使用不再赘述,网上很多帖子.左键点击这个不要放开,移动鼠标到uu加速器界面就可以只捕获uu加速器的数据了.然后按正常领取步骤全部在uu加速器上做一遍就行了,可以看到捕获了很多流量.
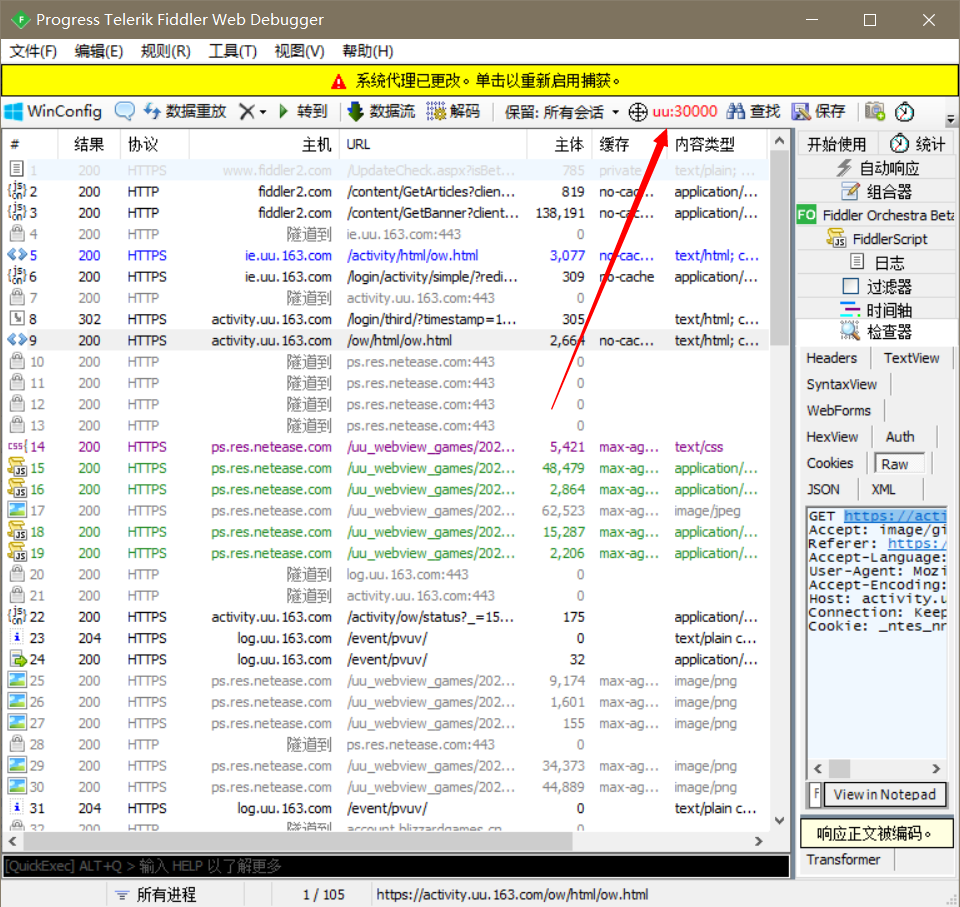
双击进去分析可以找出标号1,2是我们所需要的.这时候用python模拟这一个post就可以了.
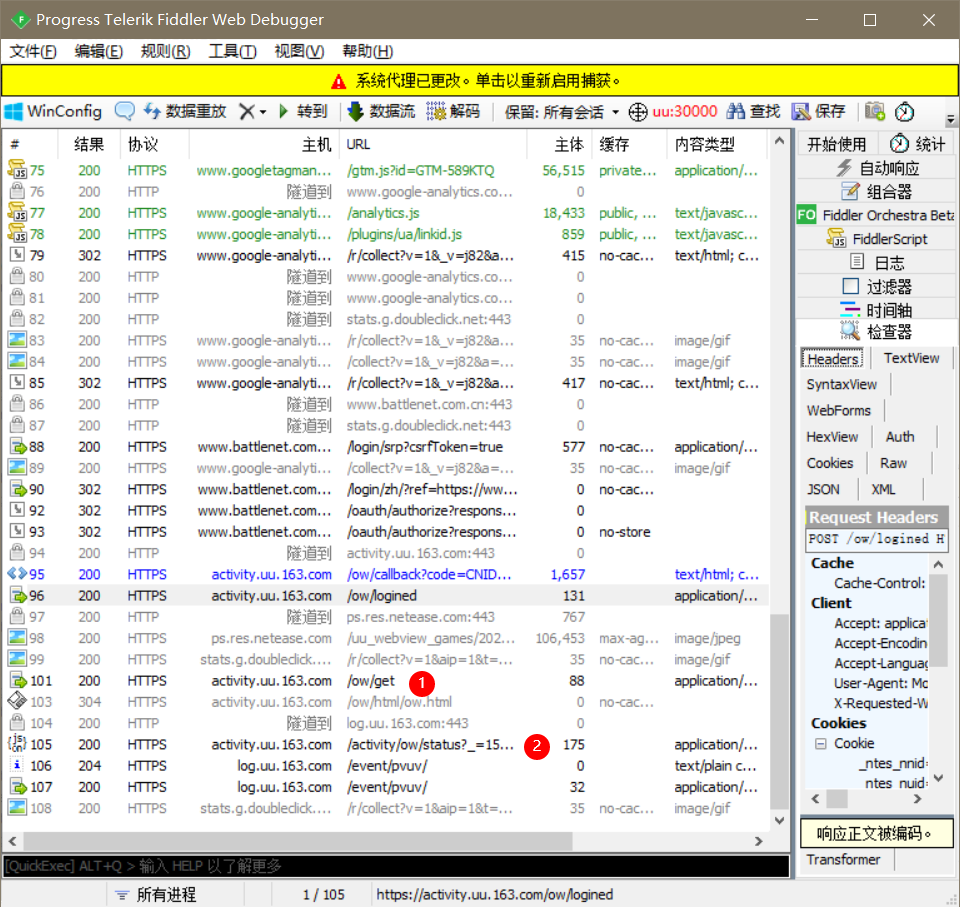
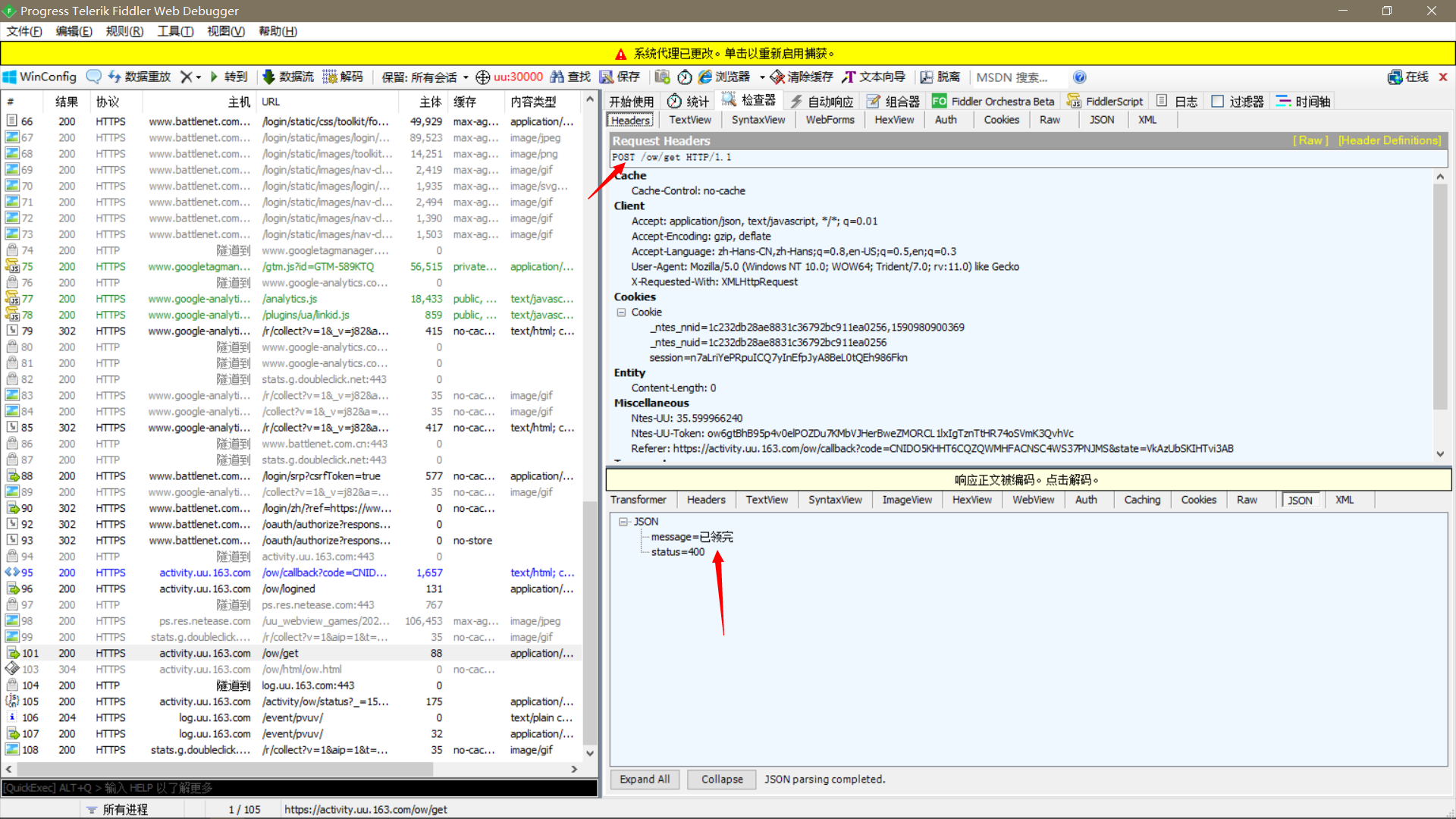
点进request中的header,右键选择 copy all Headers就可以全部复制了.然后粘贴进模块2,要去掉最后一个逗号,然后结果粘贴进模块1,运行就可以了.
下面贴代码了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| #模块一
import requests
url='https://ie.uu.163.com/activity/ow/get'
data={}
header={
'Accept':'application/json, text/javascript, */*; q=0.01',
'Ntes-UU':'10.413896146',#替换内容(抓包标号2里面有)
'Ntes-UU-Token':'DSQbPVKanQl3ohmNyWXnw5zwDxOQaOb3NhemaZBbkmL67f01yARCdpGLLjdOCmrZ',#替换内容(抓包标号2里面有)
'X-Requested-With':'XMLHttpRequest',
'Referer':'https://ie.uu.163.com/activity/ow/callback?code=CNVFSDJP2SQYFF1CDRIH4ODA9NXGL2SRV9&state=ORgBJeo4bdPuzYdB',
'Accept-Language':'zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding':'gzip, deflate',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Host':'ie.uu.163.com',
'Content-Length':'0',
'Connection':'Keep-Alive',
'Cache-Control':'no-cache',
'Cookie':'_ntes_nnid=1c232db28ae8831c36792bc911ea0256,1590980900369; _ntes_nuid=1c232db28ae8831c36792bc911ea0256; session=IeZ47FhSu7kS7uYaJoiZLE696k46_5oD-JfDO2e_' #替换内容(抓包标号2里面有)
}
r1=requests.post(url,headers=header,data=data)
print(r1.status_code)
#r.encoding='utf-8'
s=r1.text
print(s.encode('utf-8').decode("unicode_escape"))
|
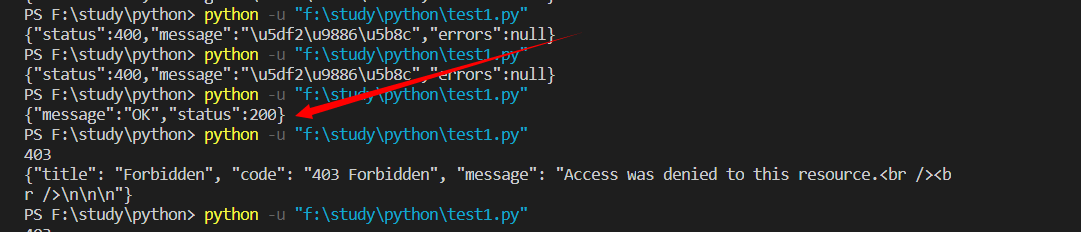
这个模块是领取模块,因为是下午做的图文,忘了截图,领取成功后再运行就403了.没法了,不能截图了,应该平常运行时显示已经领取完了,时Unicode字符,需要自己解码,在11:00那一刻,会成功显示ok
一个把headers转换成键值对的模块,最末尾会多一个逗号,删掉即可.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
import re
headers_str = """
Accept: application/json, text/javascript, */*; q=0.01
Ntes-UU: 35.597966240
Ntes-UU-Token: ow6gtBhB95p4v0elPOZDu7KMbVJHerBweZMORCL1lxIgTznTtHR74oSVmK3QvhVc
X-Requested-With: XMLHttpRequest
Referer: https://activity.uu.163.com/ow/html/ow.html
Accept-Language: zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko
Host: activity.uu.163.com
Connection: Keep-Alive
Cookie: _ntes_nnid=1c232db27ae8831c36792bc911ea0256,1590980900369; _ntes_nuid=1c232db28ae8831c36792bc911ea0256; session=n7aLriYePRpuICQ7yInEfpJyA8BeL0tQEh986Fkn
"""
pattern = '^(.*?): (.*)$'
for line in headers_str.splitlines():
print(re.sub(pattern,'\'\\1\':\'\\2\',',line))
|
10:59时疯狂运行,有一刻会显示成功
再用下面这个可以检查是否成功(也可以不用检查)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| #这个模块类似第一个模块用法,header中的内容也要替换,内容为我一个图的序号二.
import requests
url='https://activity.uu.163.com/activity/ow/status?_=1591238667404'#最后一串数字要改,在raw里面有
header={
'Accept':'application/json, text/javascript, */*; q=0.01',
'Ntes-UU':'35.599966240',#替换内容(抓包标号2里面有)
'Ntes-UU-Token':'ow6gtBhB95p4v0elPOZDu7KMbVJHerBweZMORCL1lxIgTznTtHR74oSVmK3QvhVc',#替换内容
'X-Requested-With':'XMLHttpRequest',
'Referer':'https://activity.uu.163.com/ow/html/ow.html',
'Accept-Language':'zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding':'gzip, deflate',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Host':'activity.uu.163.com',
'Connection':'Keep-Alive',
'Cookie':'_ntes_nnid=1c232db28ae8831c36792bc911ea0256,1590980900369; _ntes_nuid=1c232db28ae8831c36792bc911ea0256; session=n7aLriYePRpuICQ7yInEfpJyA8BeL0tQEh986Fkn'#替换
}
r1=requests.get(url,headers=header)
print(r1.status_code)
s=r1.text
print(s.encode("utf-8").decode("unicode_escape"))# 详细解码编码说明 https:
|
检查结果为:(最开始type=2,意思时审核中,忘了截图,等于3的时候是已经成功了)

合
模块一一运行瞬间就出结果了,模块3运行时有结果时,结果uu加速器还在转圈圈,速度果然快了很多.再等待半个小时审核就成功了.
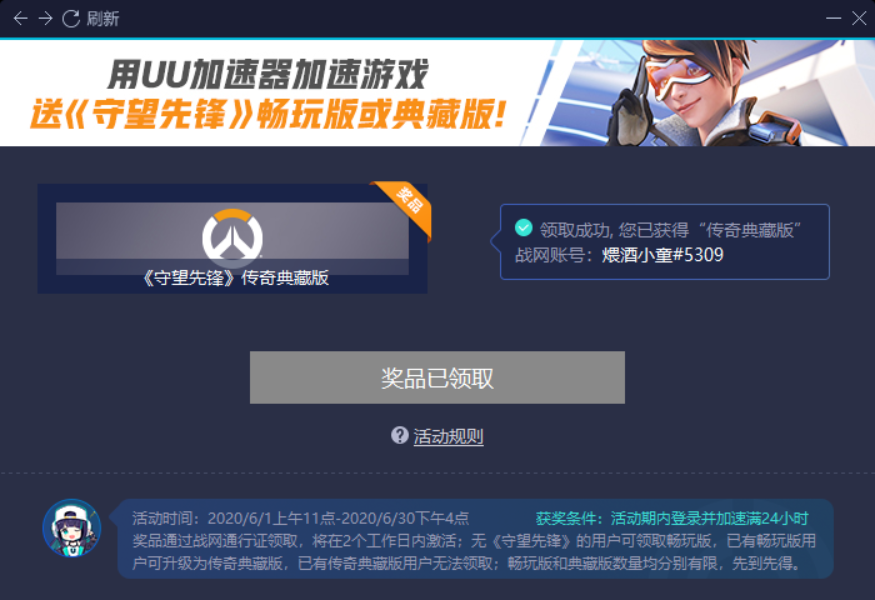
资源:抓包软件:https://wws.lanzous.com/iCMJ3dblmhe
思考:
- 太浮躁了自己,码文字时只想快快结束,写的很粗糙,应该很多没写清楚过程,只是一个堪堪思路而已
- 程序明明可以改进,这么多模块完全可以拼成一个程序,自己就是懒,总是能用就行,不想臻于完美.哎,烦(可能更怕的是自己不想面对困难,好烦(〃>目<))