1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
| from bs4 import BeautifulSoup
import re
import requests
from multiprocessing import Pool
def get_book(): #战恋雪网站所有书籍链接
try:
re=requests.get('https://www.zhanlianxue.net/')
html=re.text
soup=BeautifulSoup(html,'html.parser')
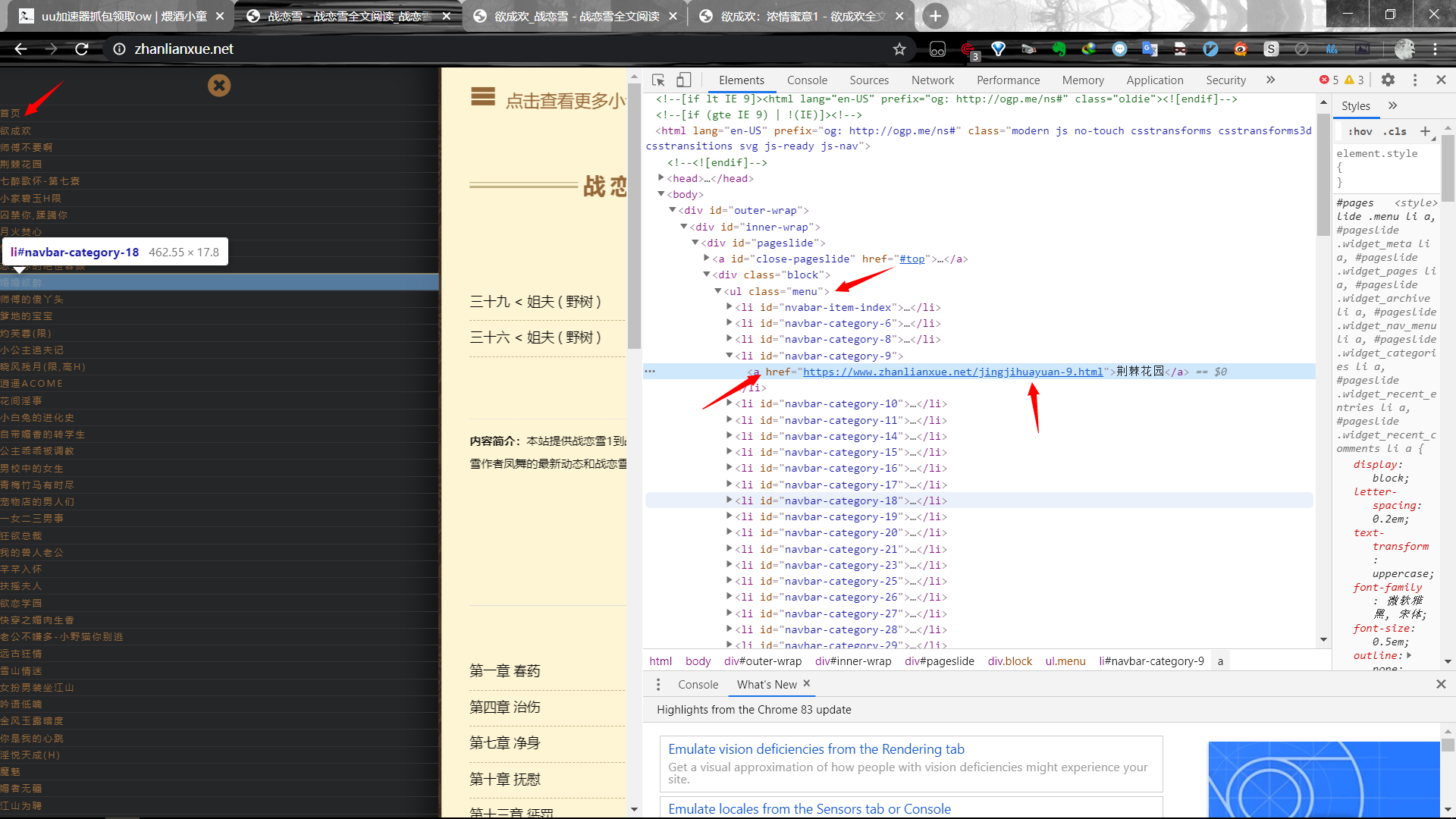
haha=soup('ul',attrs={'class':'menu'}) #ul标签可能很多,直接搜索标签会返回列表,自己找到所需内容的ul标签下标,其他的都是同理
for book in haha[0]('a'):
title=book.text
url=book.attrs['href']
if title=='首页': #有一个首页,不是一本书,需去掉
continue
yield{
'title':title,
'url':url
}
except:
print('获得所有书本信息错误')
def get_bookcapital(url): #获得一本书的所有章节名称与章节链接
try:
re=requests.get(url,timeout=60)
html=re.text
soup=BeautifulSoup(html,'html.parser')
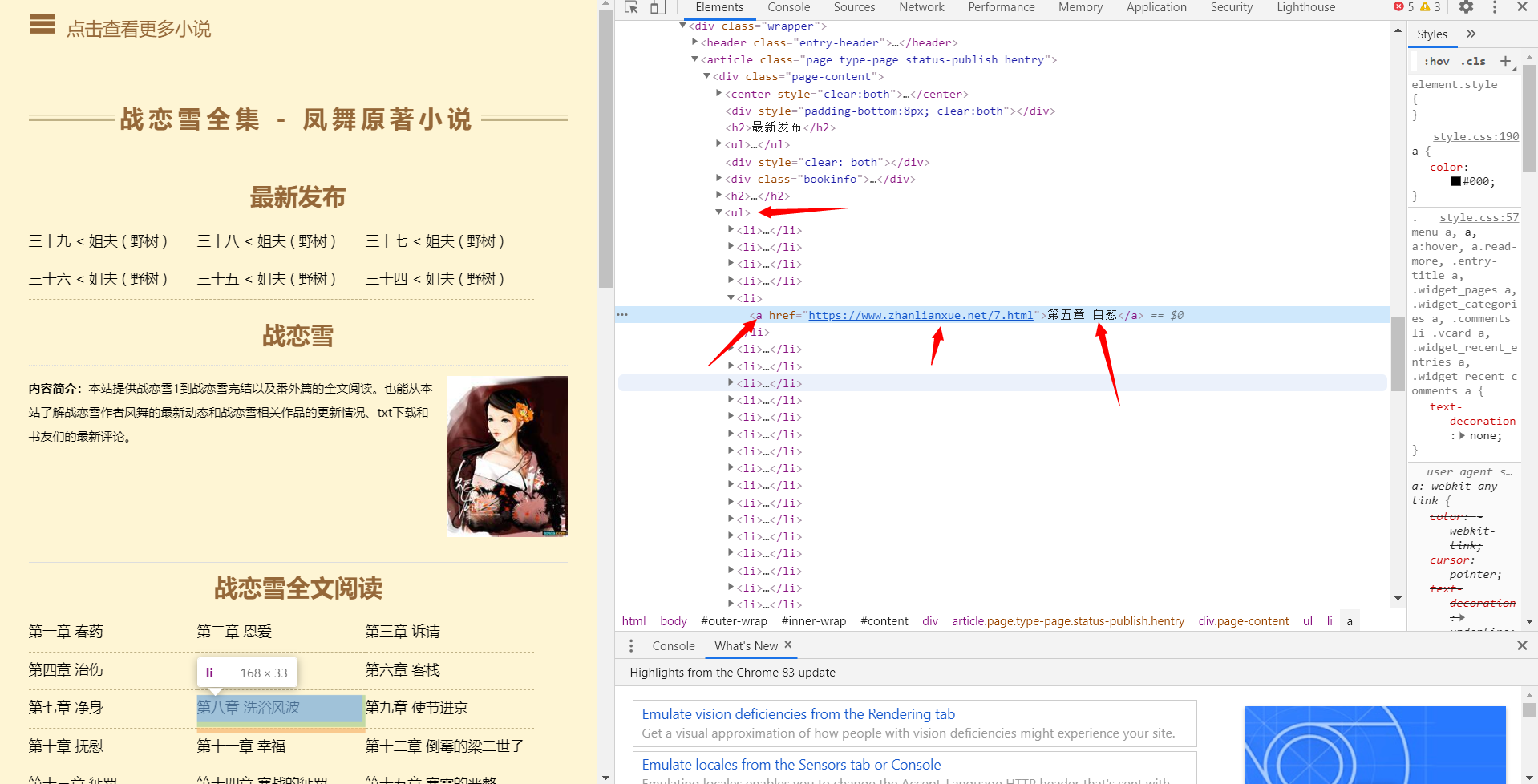
haha=soup('ul')[1]
for chapter in haha('li'):
title=chapter('a')[0].text
url=chapter('a')[0].attrs['href']
yield{
'ctitle':title,
'curl':url
}
except:
print('获取书的章节链接错误')
def savechapter(bookname,url): #根据章节连接,保存章节里面的文本
try:
re1=requests.get(url,timeout=60)
html=re1.text
html=re.sub('<br.*?>','\n',html)
soup=BeautifulSoup(html,'html.parser')
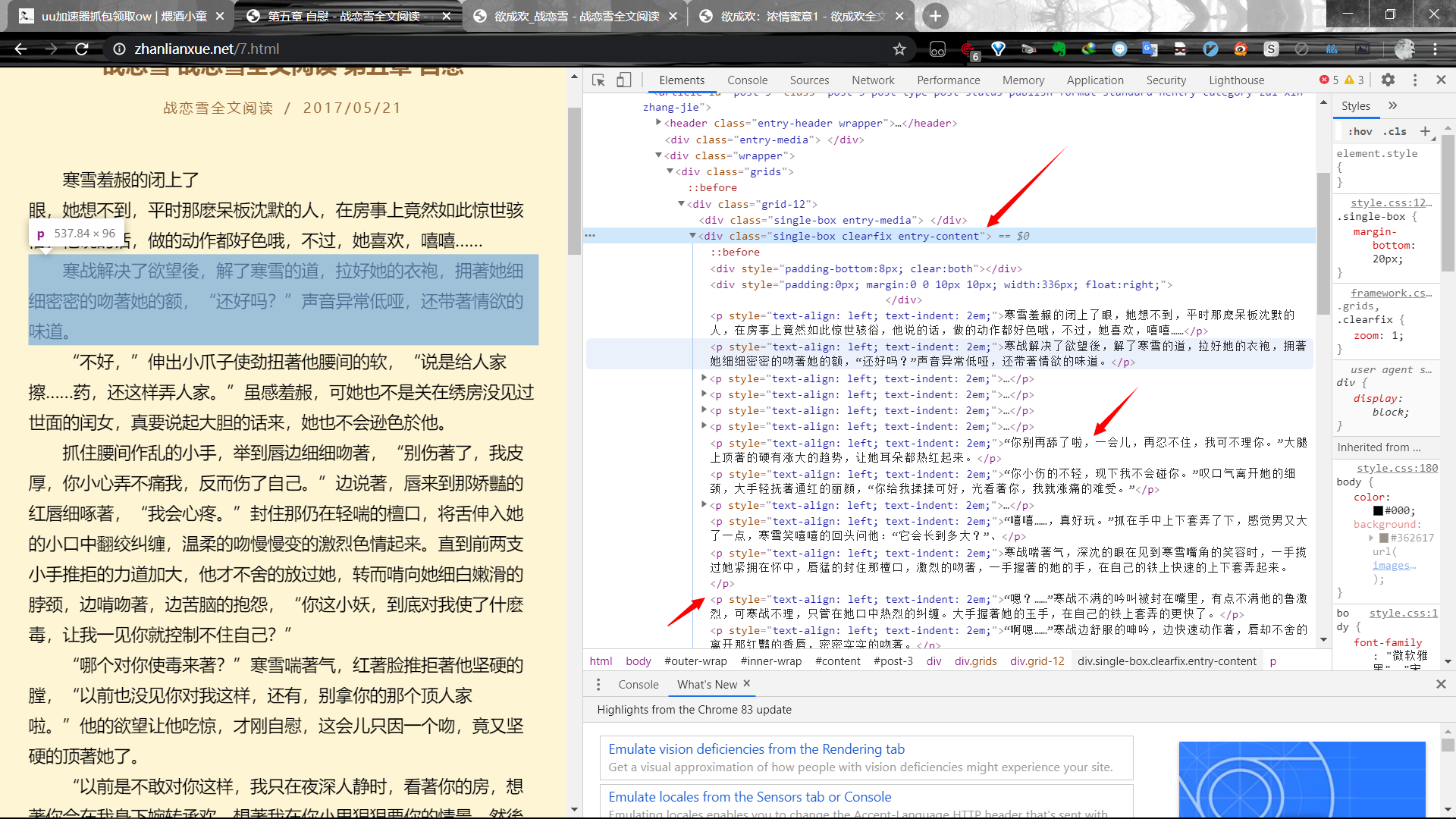
content=soup('div',attrs={'class':'single-box clearfix entry-content'})[0]
a=content('script') #清除文本中的干扰代码(美观)
for i in a:
i.clear()
makebook(bookname,content.text)
except:
print('存入文本错误')
def makebook(bookname,text): #保存文本
path='F:\战恋雪\{}.txt'.format(bookname) #这里F盘需要先创建战恋雪这个文件夹
with open(path,'a',encoding='utf-8')as haha:
haha.write('\n'+text)
def makebook_chapter(bookname,cname): #在文本中还要保存章节名称
path='F:\战恋雪\{}.txt'.format(bookname) #这里F盘需要先创建战恋雪这个文件夹
with open(path,'a',encoding='utf-8')as haha:
haha.write(cname+'\n')
def main(haha): #获得一本书的所有步骤
book=haha
print(book)
print('正在获取 {} {}'.format(book.get('title'),book.get('url')))
for chapter in get_bookcapital(book.get('url')):
print('当前《{}》--获取章节 {} {} '.format(book.get('title'),chapter.get('ctitle'),chapter.get('curl')))
makebook_chapter(book.get('title'),chapter.get('ctitle'))
savechapter(book.get('title'),chapter.get('curl'))
a=[]
for i in get_book():
a.append(i)
print(a)
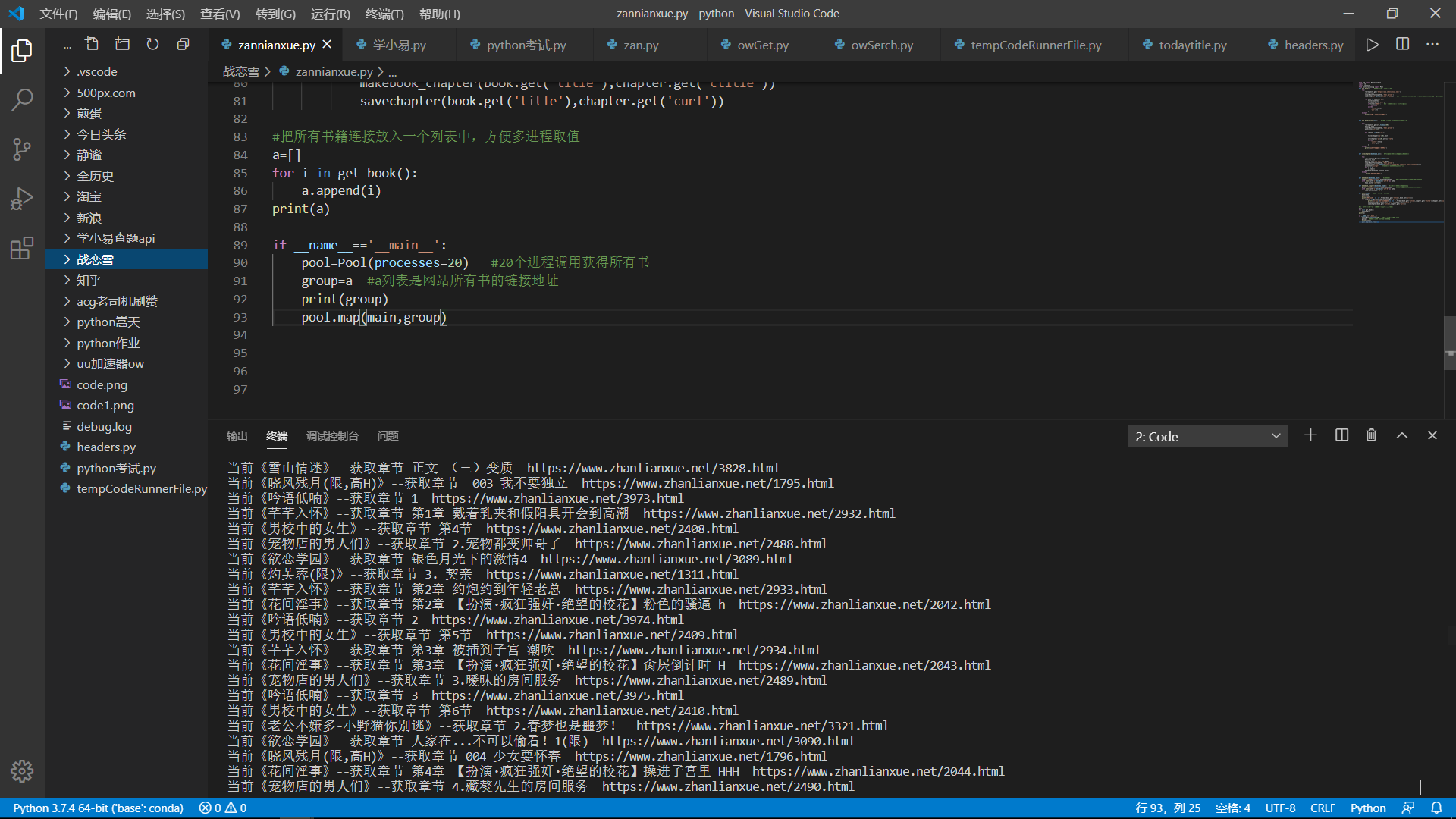
if __name__=='__main__':
pool=Pool(processes=20) #20个进程调用获得所有书
group=a #a列表是网站所有书的链接地址
print(group)
pool.map(main,group)
|