500px美图爬取
前天在逛9gag时看到了一个血脉膨胀的图,在评论区溯源于是找到了500px这个网站,根据链接进去一看,乖乖~!发现一个宝藏了,这个作者拍摄的完全是我喜欢的类型,文文艺艺,热情奔放,含而不漏,张弛有度(๐॔˃̶ᗜ˂̶๐॓)。
就是下图这样子!
起
前天在逛9gag时看到了一个血脉膨胀的图,在评论区溯源于是找到了500px这个网站,根据链接进去一看,乖乖~!发现一个宝藏了,这个作者拍摄的完全是我喜欢的类型,文文艺艺,热情奔放,含而不漏,张弛有度(๐॔˃̶ᗜ˂̶๐॓)。
就是下图这样子!
下意识的右键点击保存时,嘿,没想到遇到一个狠角色,这种防范还是我第一次见
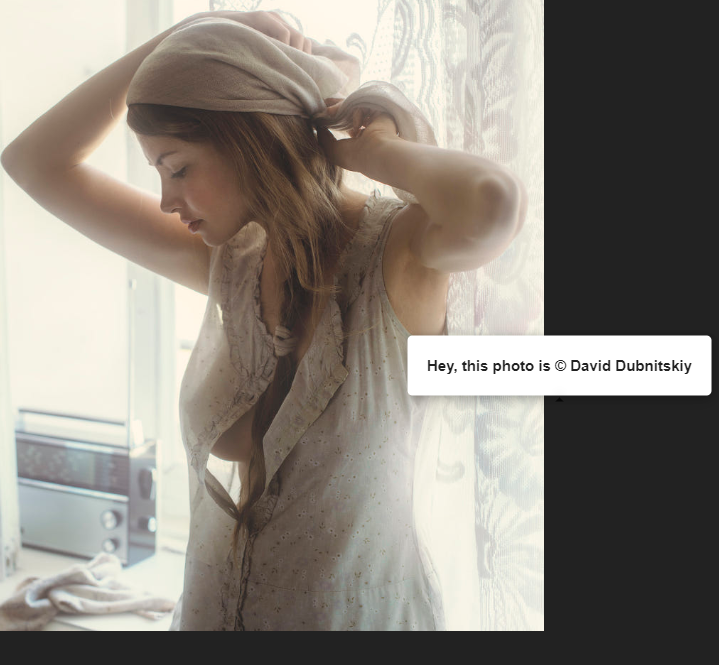
图片上右键不是平常的保存图片啥的,而是强制的弹出Hey,this photo is @author,这就很好的刺激我了,由此就开始了我的造作了。
承
在非图片区域右键直接检查元素,点击选择器定位图片元素,内容没有加密,很明显那个src的值肯定是图片真实地址了,复制在新窗口中打开,如愿的拿到图了,右键保存图片质量还行( ̄_, ̄ )
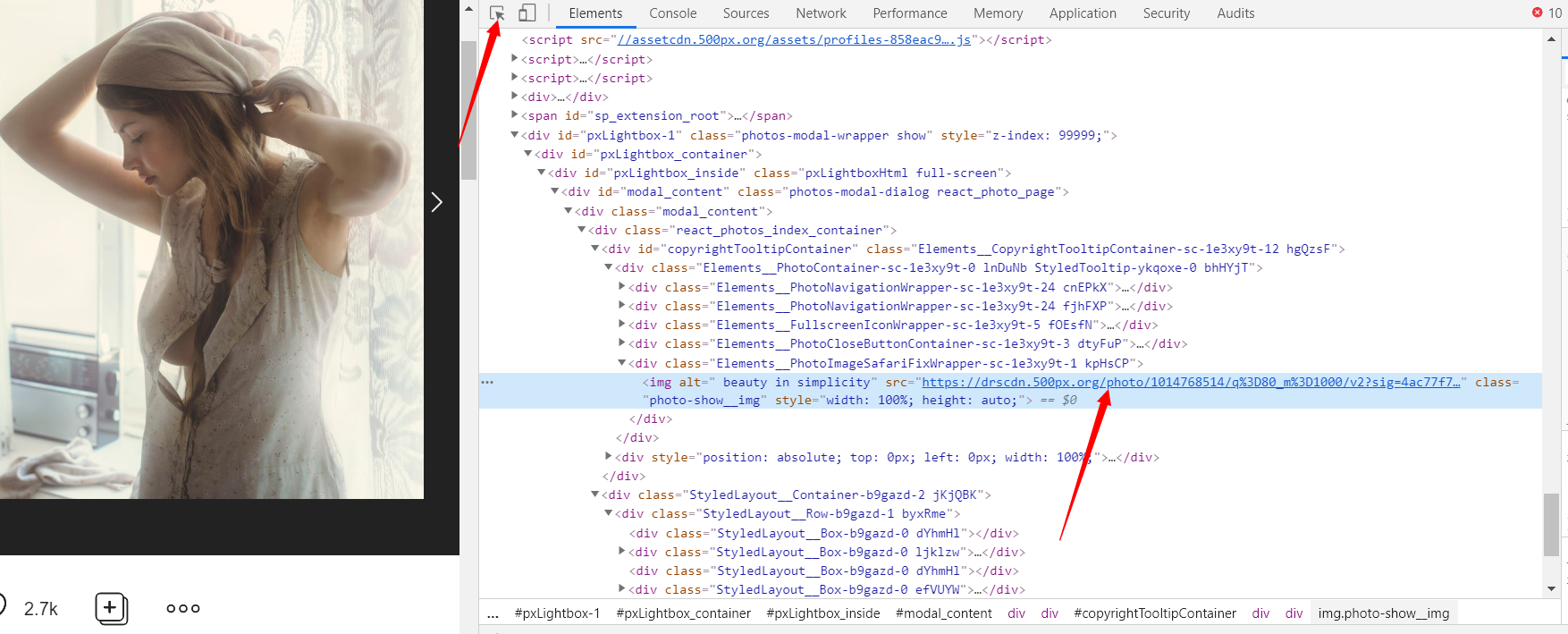
当然并不能止步于此,图片都太可口了,一个一个保存实在太累了,最好找到接口批量爬取(笑)
最开始的想法是,在作者主页面审查元素兴许包含每张图片的真实地址,如果这样直接请求这个作者的主页然后不管是正则还是煲美丽汤都可以很快的提取链接出来。
打开检查,从上一步拿到的那个真实图片地址中间复制一部分 这里我曾经爬取其他网站时走了很多弯路,因为有的链接的特征是拼接起来的,它把真实链接分成两部分,然后拼起来访问,你要是复制一整串去找绝对找不到的,所以以后我都是随机截取一小段在html源文档中搜索然后在源文档中查找,很可惜没有。
那就有可能是动态加载的了,这个时候我的思路倾向于这个图片是通过ajax加载的,ajax里面兴许包含真实链接,于是兴冲冲的就重新在主页刷新并划了几下,打开XHR(这里不选择打开图片页那里刷新是因为主页包含全部照片,这里可以找到全部照片信息的可能性最大)
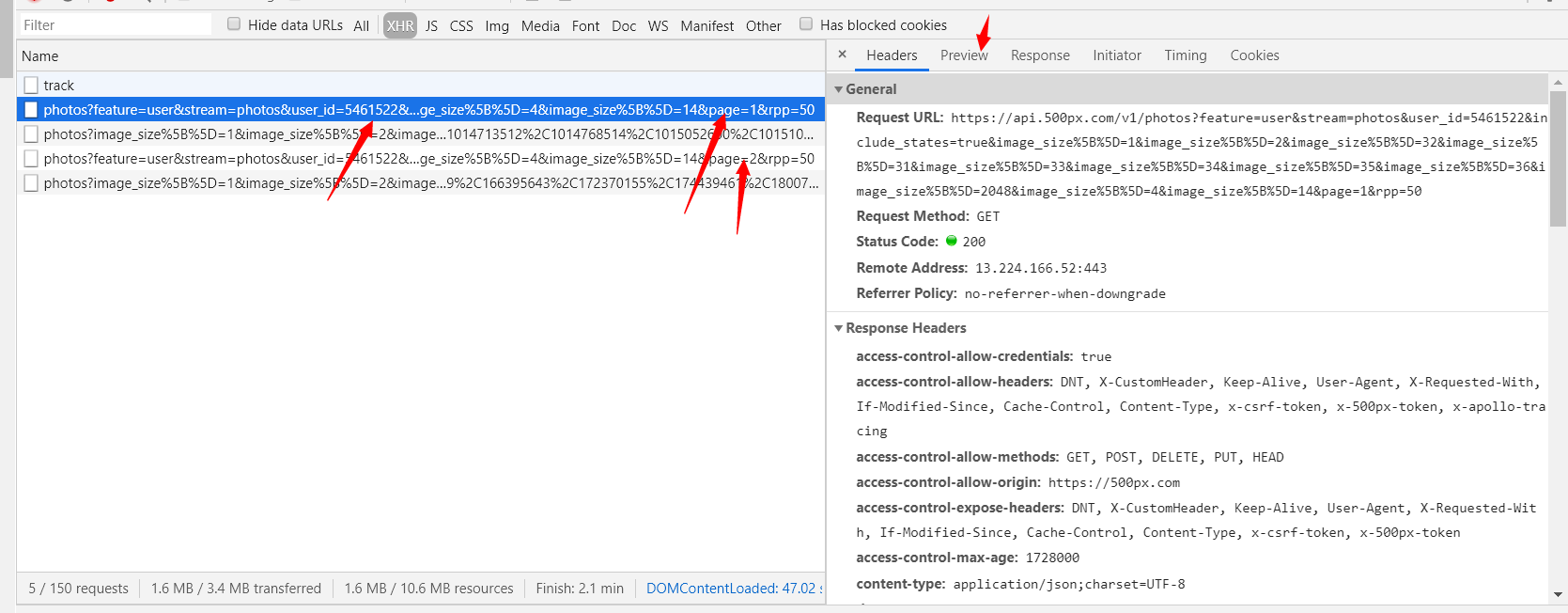
还行通过page的变化,加上点击那个Preview大致预览了一下,这就是我们要找的东西,打开Preview,如下图:
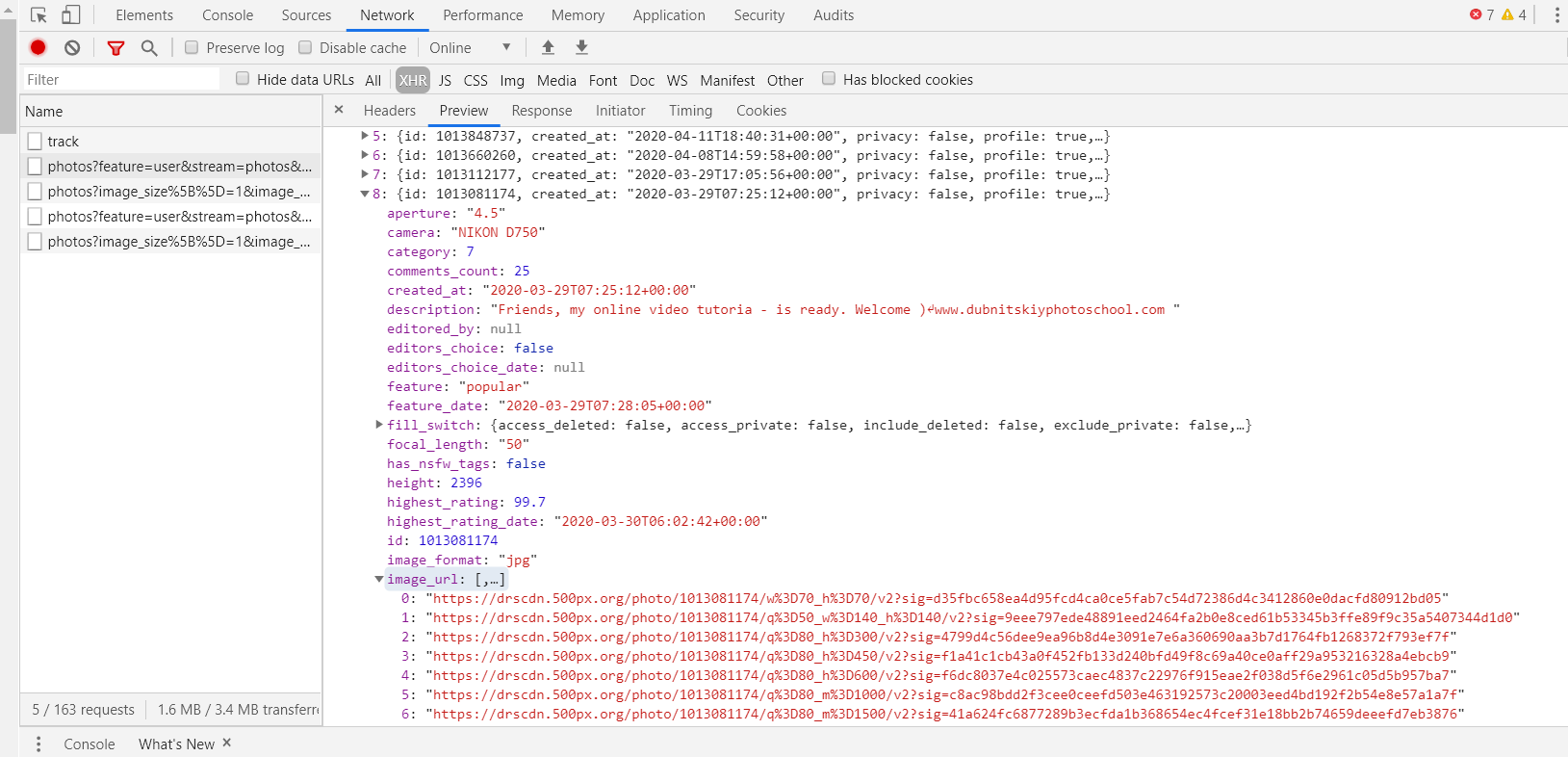
这就是我们所要的内容了,里面全是每一张的照片信息,如title,image_url等等很实在的参数,对于image_url又分了很多类,复制打开观察,发现是照片的分辨率参数,自认为最好的品质是 8 那一栏了,继续观察,这里的照片信息总共只有 50 张,这个ajax中有total_items=107,应该是 107 张照片了,total_page=3,应该就是总页数了,接下来只要找出偏移量就万事俱备了。
剩下的工作就是找不同,通过滑动主页,让剩下来的内容都加载出来,对比ajax的不同:
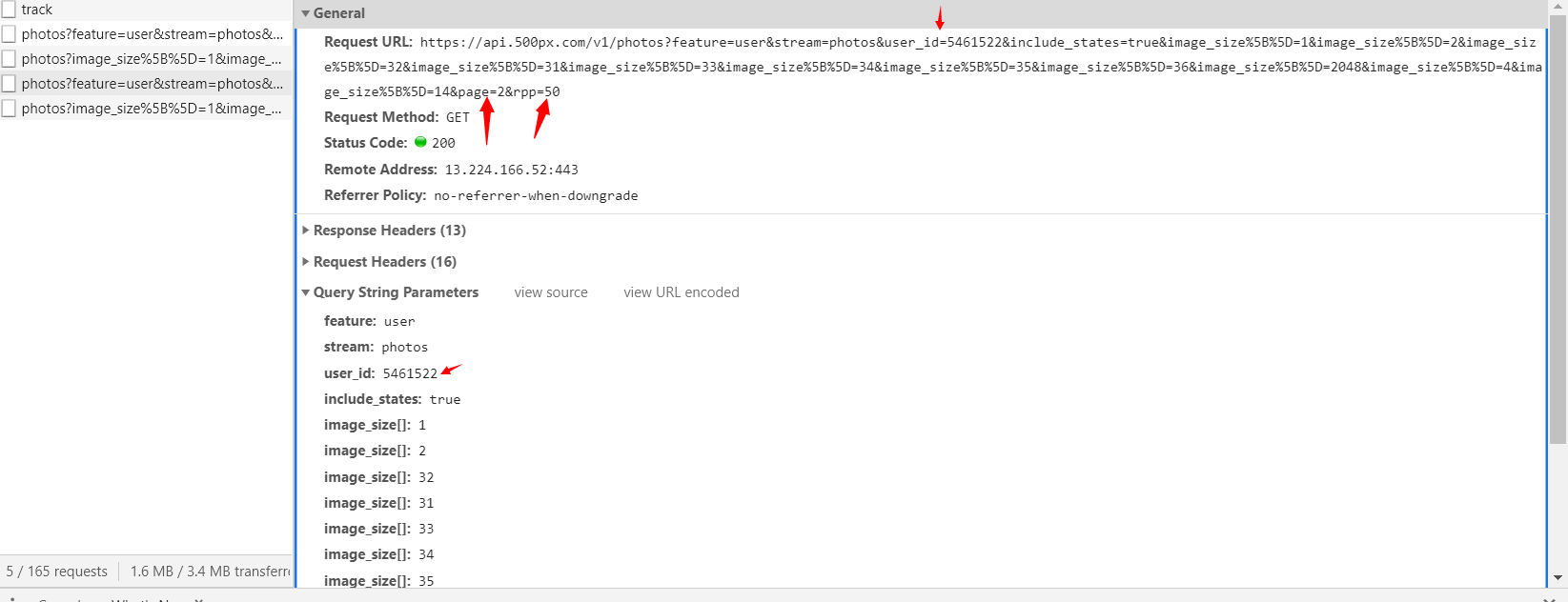
可以看出来,偏移量就是page这个参数了,user_id盲猜就是用户ID,对于rpp=50,自然的可以想到是一次性加载 50 个照片,根据总页数为 3,总照片为 107,也可以进一步证实猜测。接着也可以看到请求中包含image_size参数,对应着照片的分辨率。
实验性的复制请求去访问,发现可以得到一个刚刚分析ajax时一模一样的json字符串,再更大胆的改一下参数,rpp=200,或者把那些image_size删除一些看看有什么变化。如:https://api.500px.com/v1/photos?feature=user&stream=photos&user_id=19539&image_size%5B%5D=2048&page=1&rpp=200,多次试测试,可以得出结论,每次最多返回 100 个照片信息,且通过调节image_size参数可以让其选择性的返回品质最高的照片。
转
下面直接贴代码了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
from urllib.parse import urlencode #为了把字典型转为请求的参数
from bs4 import BeautifulSoup
import re
import requests
import json
import os
from multiprocessing import Pool
from hashlib import md5
head={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'
}
def createurl(page): #这里根据偏移量构造请求url
url='https://api.500px.com/v1/photos?'
parser={
'feature':'user',
'stream':'photos',
'user_id':'19539',
'image_size[]':'2048',
'page':page,
'rpp':'100'
}
return url+urlencode(parser) #urllencode可以字典转化为url参数中
def get_page(): #总共需要翻取多少页
head={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'
}
try:
url='https://api.500px.com/v1/photos?feature=user&stream=photos&user_id=19539&image_size%5B%5D=2048&page=1&rpp=100'
re1=requests.get(url,headers=head)
html=re1.json() #注:这儿可以直接返回字典型数据
page=html.get('total_pages')
return int(page)
except:
print('获取总翻页信息失败')
def get_detiel(url): #取得照片的url,title,formatp(格式信息)
head={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'
}
try:
re1=requests.get(url,headers=head)
html=re1.json()
page=html.get('total_pages')
photos=html.get('photos')
for i in photos:
url=i.get('image_url')[0]
title=i.get('name')
formatp=i.get('image_format')
yield{
'url':url,
'title':title,
'formatp':formatp
}
except:
print('获取所有照片信息失败')
def lsit_photo(): #这里吧照片信息全部装到一个列表中,为了后面使用多进程
list1=[]
total=get_page()
print(total)
for i in range(1,total+1):
url=createurl(i)
for photo in get_detiel(url):
list1.append(photo)
return list1
def save_phtot(photo): #
global ppt
global error
try:
a=photo.get('title')
a=a.replace(r'\n','') #这里作者起名很怪,打了回车键,若是不处理在保存时因为有\n不好处理故把换行符去掉
a=a.strip() #进一步规范title
path=r'F:\500px摄影\19539\{}----{}.{}'.format(a,ppt,photo.get('formatp'))
ppt+=1 # 作者更丧心病狂的取同样的名字,疯狂报错再次添加变量,用md5的话一大串字符太丑了
with open(path,'wb')as haha:
print('正在保存:{}'.format(photo.get('url')))
content=requests.get(photo.get('url'),headers=head).content
haha.write(content)
except:
print('保存文件{}====={} error'.format(path,photo.get('url')))
errordit={
'url':photo.get('url'),
'title':photo.get('title'),
'formatp':photo.get('formatp')
}
error.append(errordit) #这个函数因为很多次报错,总有保存不成功的,于是就把错误的收集起来可以进行二次保存 。。然鹅好像没有用。。。。懒得改了
all=lsit_photo()
print(len(all))
#print(all)
ppt=0
error=[]
# for i in all:
# save_phtot(i)
def main(photo):
save_phtot(photo)
if __name__=='__main__':
pool=Pool(processes=50) #50个进程
pool.map(main,all)
print(error)
1 | |
合
思考:
- 这个网站表面做的很严,但内部竟然毫不设防,就连反扒措施也只是限制于请求来源,可以肆无忌惮的提取数据,有点奇怪
- 找到网站api我没有花费很多时间,关键是提取数据花费了很多时间,需要多多熟练语法
- 其实那个user_id还可以做很大的文章,根据作者的关注列表可以找遍很多优秀的摄像作品,兴许还可以统计统计这个网站的摄影器材的种类,镜头啥的,没兴趣弄了(笑)主要是不会