近来遇到一个es查询商品使用ik分词器,召回结果不准确的问题,比如搜索 洗衣液,返回出洁厕液。选择的分词方式是 ik_max_word.出现的原因是分词会把“液”这个单字分开进行索引所以查询错误。如果不想要这个“液”单独分出来需要设置停止词库
常用词库:
百度停用词表等
搜狗词库转换scel转换工具
GET /_analyze { "analyzer": "ik_max_word", "text":"洗衣液" }
查询结果为

在es插件目录配置es/plugins/ik/config/IKAnalyzer.cfg.xml停止词路径,并重启es生效,词典同理。
1
2
3
| <entry key="ext_stopwords">haha.dic</entry>
或者放到其他目录
<entry key="ext_stopwords">./mydict/haha.dic</entry>
|
ik词库热更新过程
配置文件也有远程拓展词典,远程拓展词典可以放在nginx或者自己后台一个传输文件流的地址。
ik会每60秒通过head请求头文件的ETag与Last-Modified进行对比判断设置的词典是否更新。如果有任一个变动才会get请求,请求词典资源。
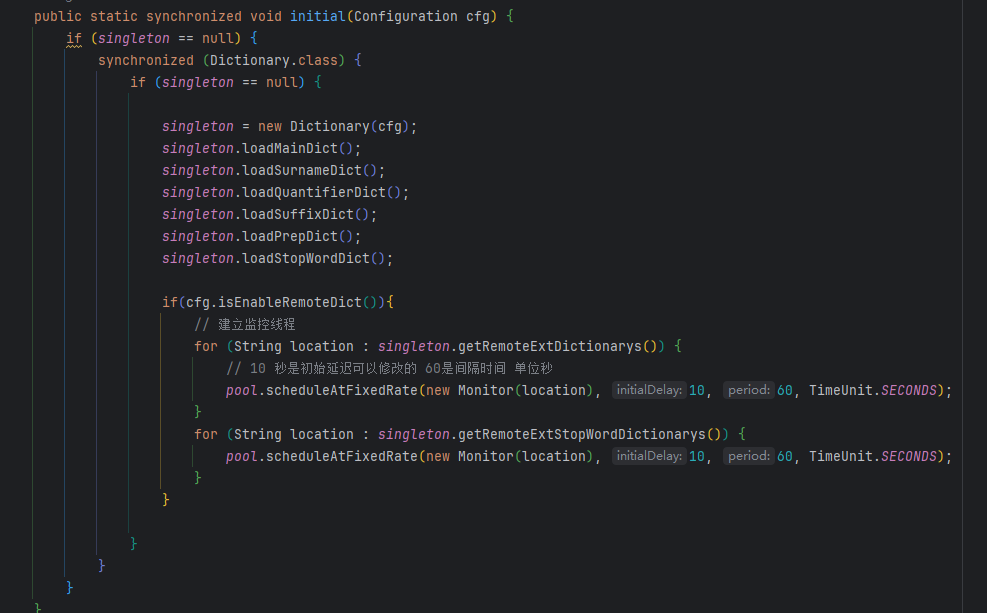
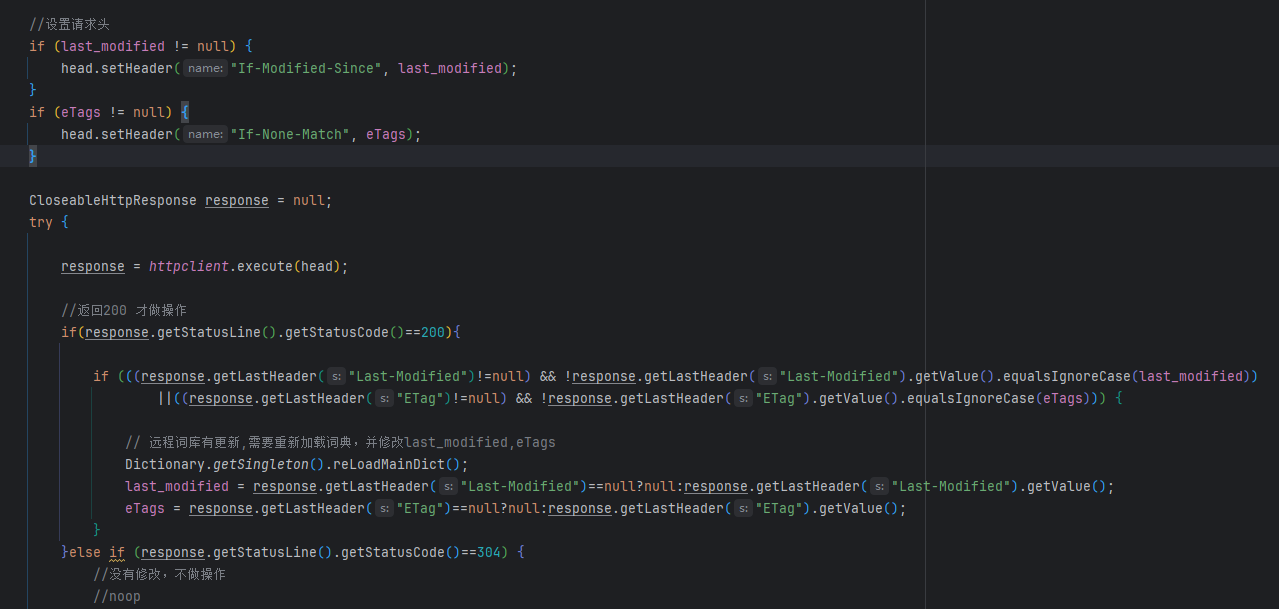
数据库热更新
对于head请求返回最新ETag即可。怎么知道数据库词典变动一条数据后,通知ik呢?也就是返回的ETag要与ik存的ETag不一致。需要存储一个newTag 标签。每当词典有变动后标签+1。在head请求时,把这个newTag的值塞入ETag就可以了。
集群情况
对于newTag标签,单机直接放入内存即可,多服务需要把newTag存入数据库,这里存入的是redis。
如果是es集群 ,当词典更新后,我们需要更改各个机器newTag以通知ik进行get请求,需要为每一个机器设置一个newTag。通过访问的机器id找到机器对应的newTag返回出去。
服务端:
有个坑
@GetMapping(value = “/syncStopIkDic/{machine}”) 不能写成
@RequestMapping(value = “/syncStopIkDic/{machine}”, method = {RequestMethod.GET})。不知道原因。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| @ApiOperation(value = "更新停止词")
@GetMapping(value = "/syncStopIkDic/{machine}")
public ResponseEntity<String> getHotWordByOracle(@PathVariable("machine") String machine){
HttpHeaders headers = new HttpHeaders();
String content = esStopwordsDicBiz.getStopWordByMysql(machine);
headers.add(HttpHeaders.CONTENT_DISPOSITION, "attachment; filename=stopWrodfile.txt");
return ResponseEntity.ok()
.headers(headers)
.contentType(MediaType.parseMediaType("text/plain;charset=UTF-8"))
.body(content);
}
@ApiOperation(value = "停止词是否变动")
@RequestMapping(value = "/syncStopIkDic/{machine}", method = {RequestMethod.HEAD})
public ResponseEntity<String> shouldSync(@PathVariable("machine") String machine){
Long newStopTag = esDicRedisService.getTagValue(RediskeyEsDicConstants.ESIK_NEW_STOPWORLD_TAG, machine);
HttpHeaders headers = new HttpHeaders();
headers.add("ETag",newStopTag+"");
return ResponseEntity.ok()
.headers(headers).body("");
}
@Override
public String getStopWordByMysql(String machine) {
String res = "";
String stopDicsRes = esStopDicService.list().parallelStream()
.map(EsStopwordsDic::getStopword).collect(Collectors.joining("\n"));
res = stopDicsRes;
return res;
}
|
每当一个es机器进行访问的时候把他的机器id用set集合保存起来,方便后续批量更改。
redis key 这样设计,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
String ESIK_NEW_STOPWORLD_TAG = "es:ik:{machine}:new:stopword";
String ESIK_NEW_MAINWORLD_TAG = "es:ik:{machine}:new:mainword";
String ESIK_MACHINE = "es:ik:machine";
|
实际es存储结构

返回newTag值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
@Override
public Long getTagValue(String key, String machine) {
key = key.replace("{machine}",machine);
Object o = jedisService.get(key);
if(o == null){
jedisService.jsset(RediskeyEsDicConstants.ESIK_MACHINE, machine);
jedisService.getJedis().set(key, "0");
return 0L;
}
return Long.parseLong(o.toString());
}
|
数据库插入停止词代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
public EsStopwordsDicDTO afterSave(Boolean saveResult, EsStopwordsDicDTO t){
if(saveResult){
esDicRedisService.addOneForTagValue(RediskeyEsDicConstants.ESIK_NEW_STOPWORLD_TAG);
}
return t;
}
public Boolean addOneForTagValue(String key) {
Set<String> redisRes = jedisService.getJedis().smembers(RediskeyEsDicConstants.ESIK_MACHINE);
Pipeline pipeline = jedisService.getJedis().pipelined();
redisRes.forEach(machine -> {
JdCore jdCore = JSONUtil.toBean(machine, JdCore.class);
String machineId = (String)jdCore.getT(String.class);
pipeline.incr(key.replace("{machine}",machineId));
});
pipeline.sync();
return true;
}
|