电商语料VOC标签分类方案
VOC(Voice of Customer,客户之声)的目标是通过分析客服与顾客的聊天记录、订单评价等内容,识别顾客意图并归类打标,帮助商家洞察用户真实需求,反哺产品迭代和客服话术优化。
本文记录在对接淘宝平台实时消息队列、做电商场景 VOC 标签分类时,踩过的坑以及最终落地的「反向打标签 + RAG」方案。
先放一张整体架构图,有个全貌印象,下文按章节拆解每个环节。
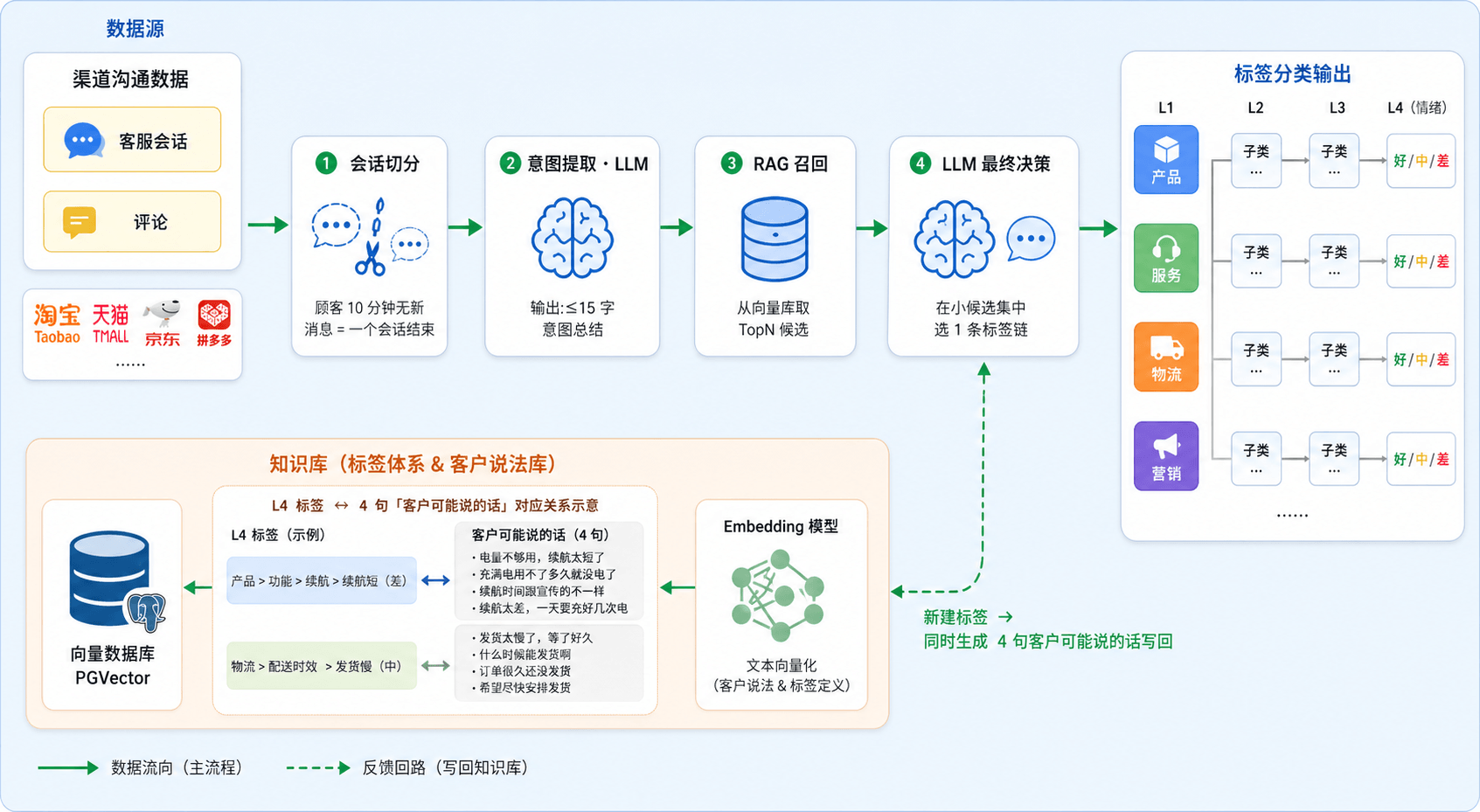
数据准备:会话分割
对接淘宝实时消息队列时,需要自己手动切分顾客的聊天会话。约定的分割规则是:
顾客超过 10 分钟没有产生新消息,即视为本轮会话结束。
由此带来的几个事实:
- 一个会话包含多条聊天记录
- 同一顾客一天可以产生多个会话
- 后续所有分析都以「会话」为最小处理单元
会话分析的核心,就是识别顾客意图,并把意图归入已有的标签体系。
标签体系设计

整体标签体系设计为 4 层树形结构,以下简称 L1、L2、L3、L4。
| 层级 | 内容 | 是否固定 |
|---|---|---|
| L1 | 产品 / 服务 / 物流 / 营销 | 固定四类,覆盖电商客服几乎所有场景 |
| L2 | 一级类目下的细分方向 | 动态生成 |
| L3 | 咨询的具体内容 | 动态生成 |
| L4 | 最细粒度的细节,带情绪标记(好/中/差) | 动态生成 |
为什么 L2~L4 不预定义?
- 自己维护一套全行业通用的固定模版,代价很大,且做不到千人千面
- 为每个行业单独适配一套模版,后期维护工作量爆炸
- 让商家自己维护标签也不靠谱,老板们普遍希望「开箱即用」
所以这三层交给 LLM 动态判断:是否复用已有标签,还是新增一个标签。
架构设计
让 LLM 自由判断「标签复用 / 新增」,会撞上两个业务问题:
- 标签归类不准 —— LLM 输出不稳定
- 标签无限膨胀 —— 长期来说会收敛增长速度,但是会一直增长下去
直接梭哈
最直接的想法:把库里所有标签和会话聊天记录一股脑塞给 LLM,让它分析意图、打上标签。
这条路走不通:
- 标签膨胀到上千个时,全塞给 LLM 会稀释注意力,且会触发上下文超限
- 不分级、不剪枝直接匹配,准确率肯定不够
分级剪枝
进一步想:既然是树形结构,只要锁定某条枝丫,候选范围就会大幅缩减,注意力稀释和上下文超限都能缓解。
但这条路有个暗礁——L1 写死成「产品 / 服务 / 物流 / 营销」四类,让 LLM 第一步就做这级分类决策,语义边界天然模糊:
- 「产品咨询」 → LLM 经常同时归到「产品」和「服务」
- 「物流咨询」 → 又会被归到「服务」
第一级就走错,后面更加会错得离离原上谱。哪怕系统提示词写得再细,数据量大的时候,也会出现问题。再加上多级分类需要多次调用,而且4级最终可能还需要分批 LLM,延迟与成本也太大了。
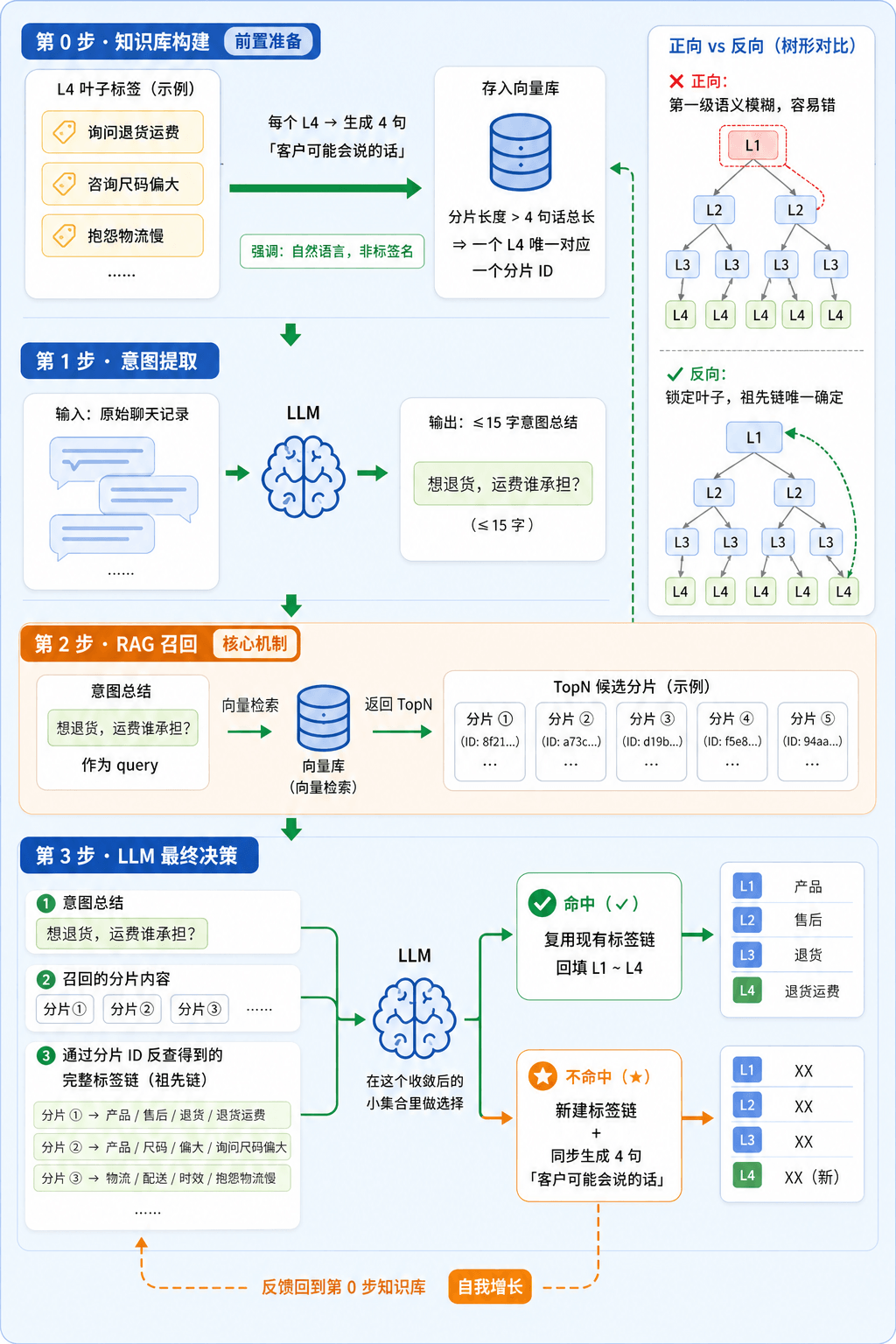
反向打标签:从叶子节点回溯
换个思路:不正向往下分类,而是反向直接锁定 L4。
核心逻辑很简单:
- 假定 L4 叶子节点可以匹配得准
- 因为是树形结构,叶子节点确定了,祖先链就唯一确定了
- 从叶子往上回溯,整条 L1 → L2 → L3 → L4 的标签链就锁住了
但 L4 叶子节点同样会膨胀到上千个,不能直接全部丢给 LLM 匹配,成本和注意力问题又会回来。
用 RAG 给 LLM 做漏斗
解决方案是引入 RAG,把上千个候选先收敛成几个,再交给 LLM 决策。
第 0 步:构建知识库
- 制作一批全行业通用的预定义标签作为冷启动种子
- 给每个 L4 标签关联约 4 句「客户可能说的话」(自然语言,而不是标签名本身)
- 这些话存入向量知识库,分片长度要大于这 4 句话的总长,确保一个 L4 标签唯一对应一个分片 ID
关键设计:用「自然语言」匹配「自然语言」准确率才高。顾客说话方式和标签命名方式天然不一样,直接拿标签名做向量检索效果会差很多。
第 1 步:意图提取
把整段聊天记录交给 LLM,提取顾客意图,做一段 15 字以内的简洁总结。
第 2 步:RAG 召回
拿每个意图总结去知识库做向量检索,得到 TopN 分片,实际上就是召回了「最像顾客这句话的几条自然语言候选」。
第 3 步:LLM 做最终决策
把以下三样一起喂给 LLM:
- 意图总结
- 召回的分片内容
- 通过分片 ID 反查得到的完整标签链
LLM 在这个已经收敛的小候选集里做选择:
- 命中 → 直接复用,顺着标签链回填 L1~L4
- 不命中 → 让它自建一条新标签链,并同时生成 4 句「客户可能说的话」写回知识库,完成自我进化
至此,一个顾客会话的标签就打完了。
上面四步流程串起来,完整工作机制如下图。
方案小结
反向打标签 + RAG 的优势:
- 范围可控:即使标签膨胀到上千个,LLM 每次面对的也只是 RAG 召回的固定小范围
- 准确率高:跳过模糊的中间层级决策,只在最具体的叶子层做一次语义匹配
- 同模型惯性好:同一模型在相同知识库下,标签命中具有很强的一致性
- 自我增长:新建标签时同步写回「客户可能说的话」,知识库会自然扩展、越用越准
不让 LLM 做「分类决策」,只让它做「语义匹配」;把发散的归类问题(膨胀到上千类)收敛成在 RAG 召回的小范围里挑一个的问题。